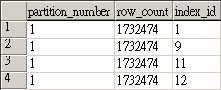
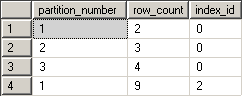
SQL Server 資料庫中的索引是用來加速查詢效率的一種方式, 利用了空間換取時間的方法來將查詢的速度增加.
既然是利用空間換取時間的方法, 代表著該存放的空間, 資料的排列狀況就會隨著時間的過去, 有資料的新增, 刪除, 修改時, 造成的索引離散狀況, 若是索引離散時, 代表著存取這些索引的 IO 量會增加, 也代表著效率會下降的狀況會發生.
如何查詢這個資料, 可以參考這篇文章: http://sharedderrick.blogspot.com/2010/02/index-fragmentation.html 有詳細的說明, 利用該查詢指令, 若是要查找特定 table 的話, 可以這樣下(SQL Server 2005以上版本):
SELECT sch.name N’結構描述’, obj.name N’資料表’,
inx.name AS N’索引名稱’,
index_type_desc N’索引類型’,
avg_fragmentation_in_percent ‘片段(%)’,
avg_page_space_used_in_percent N’頁面飽和度(%)’,
fragment_count,
avg_fragment_size_in_pages,
page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID(‘TABLE_NAME’),NULL, NULL, ‘SAMPLED’) AS phy
INNER JOIN sys.indexes AS inx ON phy.object_id = inx.object_id AND phy.index_id = inx.index_id
INNER JOIN sys.objects AS obj ON phy.object_id = obj.object_id
INNER JOIN sys.schemas AS sch ON obj.schema_id = sch.schema_id
WHERE index_type_desc <> ‘HEAP’ AND fragment_count IS NOT NULL AND avg_fragment_size_in_pages IS NOT NULL
ORDER BY 5 DESC
利用了 OBJECT_ID() 函數, 把 table 的 object id 找出來, 便能指定查找特定 table 中的索引離散狀況.
根據微軟官方的資料: http://technet.microsoft.com/zh-tw/library/ms189858.aspx , 離散狀況在 5% 以下不需要調整, 在 5% ~ 30%之間, 可以利用 ALTER INDEX REORGNIZE 來進行重組, 而大於 30% 時, 可以使用 ALTER INDEX REBUILD (ONLINE = ON) 來進行索引重建.
不過若系統效能允許的狀況下, 其實也是可以直接使用 DROP INDEX, CREATE INDEX 的方式來重建的.
其他相關文章一併整理如下:
Microsoft SQL Server 2000 Index Defragmentation Best Practices
http://technet.microsoft.com/en-us/library/cc966523.aspx
sys.dm_db_index_physical_stats (Transact-SQL)
http://technet.microsoft.com/zh-tw/library/ms188917.aspx
ALTER INDEX (Transact-SQL)
http://msdn.microsoft.com/en-us/library/ms188388.aspx
Table and Index size in SQL Server
http://stackoverflow.com/questions/316831/table-and-index-size-in-sql-server
SQL Server Indexes
http://odetocode.com/articles/70.aspx