在 wordpress 中, 預設的字型(英數)是 Georgia, 這個字型還蠻好看的, 所以在 wordpress 內寫英文字句都令人很賞心閱目, 而今天又發現另一個字型也有這樣的特性, 是 Constantia. 這兩種字型的特性, 就是英數時, 會高高低低的, 有一種硬硬的打字機的感覺. 這樣將在 word 中使用該兩種字體的圖擷下來供參考:


在 wordpress 中, 預設的字型(英數)是 Georgia, 這個字型還蠻好看的, 所以在 wordpress 內寫英文字句都令人很賞心閱目, 而今天又發現另一個字型也有這樣的特性, 是 Constantia. 這兩種字型的特性, 就是英數時, 會高高低低的, 有一種硬硬的打字機的感覺. 這樣將在 word 中使用該兩種字體的圖擷下來供參考:
原來在版本 2.6 時已經有了一個很特別的新功能, 稱之前 post revisions, 也就是文章版本管理(控制), 這個功能還蠻強大好用的, 一方面像是時光還原器, 一方面還能做版本比對, 的確是對於寫長篇大論的文章有非常方便之處, 而且其實有時若是沒有存到檔, 配合的 auto save 功能也能發揮作用, 讓損失降到最低.
預設功能在發表文章頁面上, 有個”文章版本”, 這個區塊, 如下:
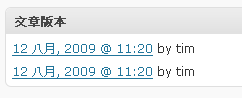
點擊進去後, 就可以看到一個很友善的版本選擇及管理功能, 如下:
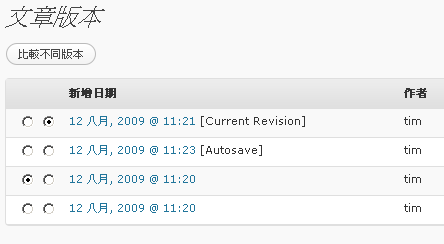
然後可以挑選要比較的版本, 並按下[比較不同版本]後, 就可以列出兩個比較, 如下:

如此一來, 便能一目了然, 方便文章的撰寫, (真的是在寫文章編輯的好工具), 這樣的計設, 功能真的很強大.
當然, 有這個功能, 也會需要一些空間來存放, 若是覺得會浪費空間或是要刪除這個備份, 當然也有可以取消地方, 可以參考: http://blog.dogg3h.com/how-to-disable-wordpress-post-revision
原來我現在才發現這個功能, 真的 lag 很久耶.
升上了2.7之後, 就有後台自動更新的功能, 不需要手動下載, 然後上傳等煩瑣的步驟來進行更新. 利用後台的自動更新, 將版本昇到 2.8.2 了, 並附上成功更新的畫面, 基本上, 真的是太人性化的設計了耶.

不過其實更新前一樣都要先做好備份網站程式及資料庫的工作, 才不會發生問題時, 沒得補救哦.
真是好消息, wordpress 2.8 release 了, 請參考: http://wordpress.org/development/2009/06/wordpress-28/ , 不過, 回到 http://mu.wordpress.com/ 時, 發現 mu 版本並未一併更新, 通常應該會遲一點, 不過可以先看看官方 blog 中的 wordpress 2.8 介紹, 先了解一下新增的功能.
屆時有 wordpress for mu 2.8 release 時, 再來進行升級更新, 不過其實目前的 wordpress for mu 我已經覺得很好用也很方便了, 期待它的新版本更新, 能修掉一些 bug 並強化更多功能.
由於資料量龐大, 為能改善效能, SQL Server 2005 增加了 Partition Table 功能將 table 依 partition function 來做分塊”橫切”的方式存放, 以將常用資料及不常用資料(如歷史訂單資料), 做實體的存放位置劃分, 讓它實際上是同一個表, 但在存放上是在不同的 filegroup 上, 如此一來, 便能有效將資料表做分塊(分區橫切)管理, 若是 partition function 切割有效的話, 對於查詢應用及備份應用應該會有非常大的幫助.
接下來, 我們需要了解的是實作完成後的 partition table 內, 各分區的資料存放筆數狀況, 可以利用兩個系統表來操作取得, 分別為:
若是要取得某 table 名為 tblTest 這個 table 在各 partition table 中的存放筆數, 可以利用這個查詢:
SELECT ps.partition_number
,ps.row_count, ps.index_id
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.partitions p
ON ps.partition_id = p.partition_id
AND p.[object_id] = OBJECT_ID('tblUsers')
這樣取得的結果, 一般若非 partition table, 會得到一筆資料, 例如:
![]()
其中三個欄位說明如下:
若是有無切分 partition table , 但又有多個 index 的 table 會得到如下結果:
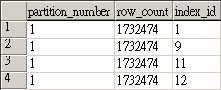
其中, 就是 1為clustered, 而9, 11, 12為 non-clustered 的資料.
再來就是看有切 partition table 的結果:
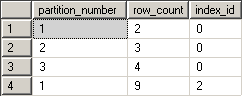
這個案例來自於這篇文章: [SQL Server]如何將現有table調整為partition table (http://bbs.diary.tw/viewtopic.php?f=13&t=464)
其中, 可以清楚地看到 index_id 為0的, 是 partition_number 為1, 2, 3的資料存放筆數狀況, 而 index_id為2的是後來利用增加 primary key non-clustered index 的方式加入的索引, 得到總筆數的一個 index 存放狀況.
簡而言之, 資料存放的方式為 parititon1 放了 2筆, partitiona2放了 3筆, partition3放了4筆資料, 這樣的查詢結果對於要查目前的 partition table內存放資料的對應 parition 狀況應該就有很清楚的結果呈現了.
這個網站原來是用 2.3.3 的版本, 但是因為版本到 2.7 之後的後台介面有長足的改善, 所以進行更新.
不過困難在於要由 1.3.3 (2.3.3) 更新到 1.5.1, 然後再升到 2.6 再升到 2.7.1, 真的很麻煩, 於是利用匯出匯入的方式, 重新安裝好 WPMU 2.7.1 之後, 再進行匯入完成.
陸續補上了 theme 及 pluglin 就完成了. 真的介面改善不少哦, 功能似乎也更強大了
在使用 Replication 時, 若是使用 Transaction 的方式, 若有要新增 article 到 publication 時, 其實很容易.
基本上就只要在原來的 publication 的 property 裡的 articles, 多加上需要 replication 出來的article, 完成後, 他不會自動進行後續, 接下來的動作就是做 snapshot 就行了, 這裡比較討厭的是若是原來的publication資料多, 而加入的 article資料少, 其實很不划算, 不過做完 snapshot 後, replication 機制會開始將該新發行的article schema傳給 subscriber, 讓 subscriber 將沒有的資料寫入, 這樣就完成了.
其實只會做新的部分, 不過因為還是要一個 schema及起始資料, 所以還是得做一個 snapshot 是比較吃資源的地方, 和 alter table的狀況又不太一樣了. 不過操作上還是很直覺也很方便!
參考SQL Server 2005 help 資料: http://msdn.microsoft.com/en-us/library/ms152493(SQL.90).aspx
其中比較重要的是這段:
After adding an article to a publication, you must create a new snapshot for the publication (and all partitions if it is a merge publication with parameterized filters). The Distribution Agent or Merge Agent then copies the schema and data for the new article to the Subscriber (it does not reinitialize the entire publication).
也就是說, 新增完了之後, 要做一次 snapshopt, 不過 agent 會將新的 article 送到 subscriber, 而不會整個 reinitialize!
若是SQL Server已設定完成Replication的Article時, 進行資料表異動, 其實會透過 DDL 傳送的方式, 將異動的指令也透過複寫的方式送出, 並進行同步. 可以參考相關文章: http://www.replicationanswers.com/AlterSchema2005.asp
不過若是異動的欄位是 Primary Key時, 將會觸發 exception, 發出如下的訊息:
Msg 4929, Level 16, State 1, Line 2
Cannot alter the table ‘tbltest’ because it is being published for replication.
如此一來便無法使用這種 ddl 傳遞的方式將 Replicated Table 的異動送出. 若是要執行這樣的異動需求, 得先解除掉發行及訂閱此 table, 才能進行調整, 調整完成後才能再重新設定回發行及訂閱, 接下來再做 snap shot 進行遞送出去.
在 IIS 中的站台設定, 可以明確地指定單一站台的 IP及 PORT, 不過無論如何設定, 預設 IIS 就會在發起 SERVICE 時, 佔用 0.0.0.0 這個 IP (也就是全部的 IP), 若是希望 IIS 不要佔用這個 IP (也就是希望能和其他佔用 80 PORT 的 SERVICE, 如 APACHE 共同使用同一台主機的狀況下), 可以利用 Support Tools 內的 httpcfg 工具來進行操作, 詳細步驟如下:
1. Click Start, and then click Run.
2. Type cmd, and then click OK to open a command prompt.
3. Type the following, where xxx.xxx.x.x is the IP address you want to add:
httpcfg set iplisten -i xxx.xxx.x.x
When this succeeds, Httpcfg returns the following:
HttpSetServiceConfiguration completed with 0To view additional status codes, see the Httpcfg help.
4. After the IP address is added, use the following command to list it:
httpcfg query iplisten
Httpcfg returns the following:
IP :xxx.xxx.x.x
5. From the command prompt, stop the HTTP service and its dependent services. To do this, type the following string at the command prompt:
net stop http /y
6. From the command prompt, restart the HTTP service and it dependent services. To do this, type the following string at the command prompt:
net start w3svc
Note When you start w3svc, all services that were stopped when HTTP was stopped will start.
進行指定 IP 的操作後, 之後 IIS 就只會佔用指定的 IP, 而不會佔用全部的預設 IP 0.0.0.0 囉! 請參考微軟 KB 資料: http://support.microsoft.com/kb/813368