
由於資料量龐大, 為能改善效能, SQL Server 2005 增加了 Partition Table 功能將 table 依 partition function 來做分塊”橫切”的方式存放, 以將常用資料及不常用資料(如歷史訂單資料), 做實體的存放位置劃分, 讓它實際上是同一個表, 但在存放上是在不同的 filegroup 上, 如此一來, 便能有效將資料表做分塊(分區橫切)管理, 若是 partition function 切割有效的話, 對於查詢應用及備份應用應該會有非常大的幫助.
接下來, 我們需要了解的是實作完成後的 partition table 內, 各分區的資料存放筆數狀況, 可以利用兩個系統表來操作取得, 分別為:
- sys.partitions : (http://msdn.microsoft.com/zh-tw/library/ms175012.aspx)
- sys.dm_db_partition_stats: (http://msdn.microsoft.com/zh-tw/library/ms187737.aspx)
若是要取得某 table 名為 tblTest 這個 table 在各 partition table 中的存放筆數, 可以利用這個查詢:
SELECT ps.partition_number
,ps.row_count, ps.index_id
FROM sys.dm_db_partition_stats ps
INNER JOIN sys.partitions p
ON ps.partition_id = p.partition_id
AND p.[object_id] = OBJECT_ID('tblUsers')
這樣取得的結果, 一般若非 partition table, 會得到一筆資料, 例如:
![]()
其中三個欄位說明如下:
- partition_number: 指對應的資料分割編號(以1為基礎), 把他想成存放的分區代碼
- row_count: 這個就是資料筆數
- index_id: 這個很重要, 0為堆積, 1為clustered, 2以上為non-clustered
若是有無切分 partition table , 但又有多個 index 的 table 會得到如下結果:
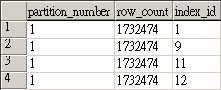
其中, 就是 1為clustered, 而9, 11, 12為 non-clustered 的資料.
再來就是看有切 partition table 的結果:
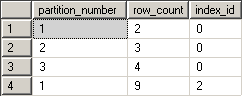
這個案例來自於這篇文章: [SQL Server]如何將現有table調整為partition table (http://bbs.diary.tw/viewtopic.php?f=13&t=464)
其中, 可以清楚地看到 index_id 為0的, 是 partition_number 為1, 2, 3的資料存放筆數狀況, 而 index_id為2的是後來利用增加 primary key non-clustered index 的方式加入的索引, 得到總筆數的一個 index 存放狀況.
簡而言之, 資料存放的方式為 parititon1 放了 2筆, partitiona2放了 3筆, partition3放了4筆資料, 這樣的查詢結果對於要查目前的 partition table內存放資料的對應 parition 狀況應該就有很清楚的結果呈現了.